

2·
2 months agoUp in the Hardware Information section of hyfetch, on the left.
Up in the Hardware Information section of hyfetch, on the left.
Not them, but I do! https://youtu.be/s1fxZ-VWs2U
Unfortunately I can’t even test Llama 3.1 in Alpaca because it refuses to download, showing some error message with the important bits cut off.
That said, the Alpaca download interface seems much more robust, allowing me to select a model and then select any version of it for download, not just apparently picking whatever version it thinks I should use. That’s an improvement for sure. On GPT4All I basically have to download the model manually if I want one that’s not the default, and when I do that there’s a decent chance it doesn’t run on GPU.
However, GPT4All allows me to plainly see how I can edit the system prompt and many other parameters the model is run with, and even configure multiple sets of parameters for the same model. That allows me to effectively pre-configure a model in much more creative ways, such as programming it to be a specific character with a specific background and mindset. I can get the Mistral model from earlier to act like anything from a very curt and emotionally neutral virtual intelligence named Jarvis to a grumpy fantasy monster whose behavior is transcribed by a narrator. GPT4All can even present an API endpoint to localhost for other programs to use.
Alpaca seems to have some degree of model customization, but I can’t tell how well it compares, probably because I’m not familiar with using ollama and I don’t feel like tinkering with it since it doesn’t want to use my GPU. The one thing I can see that’s better in it is the use of multiple models at the same time; right now GPT4All will unload one model before it loads another.
I have a fairly substantial 16gb AMD GPU, and when I load in Llama 3.1 8B Instruct 128k (Q4_0), it gives me about 12 tokens per second. That’s reasonably fast enough for me, but only 50% faster than CPU (which I test by loading mlabonne’s abliterated Q4_K_M version, which runs on CPU in GPT4All, though I have no idea if that’s actually meant to be comparable in performance).
Then I load in Nous Hermes 2 Mistral 7B DPO (also Q4_0) and it blazes through at 50+ tokens per second. So I don’t really know what’s going on there. Seems like performance varies a lot from model to model, but I don’t know enough to speculate why. I can’t even try Gemma2 models, GPT4All just crashes with them. I should probably test Alpaca to see if these perform any different there…
I actually found GPT4ALL through looking into Kompute (Vulkan Compute), and it led me to question why anyone would bother with ROCm or OpenCL at all.
I mainly recommend Universal Blue distros to newbies, like Bazzite or Aurora. The immutable nature more or less means users don’t have to worry about performing maintenance of system apps like they might on some distros, mostly don’t have to worry about dependencies, and are less likely to irreversibly break the system themselves or in an update.
That said, these distros are Fedora-based, and I think that’s fine. No idea who out there is recommending Arch of all things.
The ELI5 for Fedora’s atomic desktops is that if Windows had an Atomic Desktop version, Program Files and most of the Windows folder would be read only, and each program you installed yourself would go into its own folder in your user directory. That’s the basic idea. It’s harder to screw up an Atomic system as long as you stick to containerized app formats like flatpak/appimage whenever possible. It makes it easier for everyone to diagnose problems, and easier for users to roll back if an update has problems. Even if you were to install it right now, you could use one simple command to “roll back” to any image from the last three months.
The benefit of Bazzite is you have all of the above, plus a lot of gaming-related stuff preinstalled which, if you were to install them yourself in a normal Fedora environment, you’d likely have to spend a lot of time just learning how they’re supposed to be configured, how they interact, which versions have problems, and how to troubleshoot problems when an update to one app breaks a prerequisite for something else; eventually you end up in config hell instead of actually using your computer. With Bazzite, the image maintainers are the ones in config hell - they work out the kinks, app versioning, communicate with upstream to fix issues, all that, so your system should be in the most functional state that a Linux system can be, so you only have to think about using your apps.
tl;dr

To be fair, even in my family it’s not a full streaming replacement. We have Discovery+, Nebula, and (free) YouTube. Live TV from the Roku player is the main thing I want to replace through IPTV, either Jellyfin or maybe Kodi, but both the metadata and functionality of free sources is a crapshoot. If I could replace the Roku live TV use with some inexpensive paid IPTV source, then I could easily switch to any streaming box brand, like ONN or some other generic Android TV.
My setup is not recommended, honestly. Old gaming PC from about 14 years ago with a couple extra hard drives, thrown in the closet with stripped-down Windows 10 on an old SSD, desktop version of Jellyfin, and an external drive for backups. Not even running in a Docker container because the CMOS battery is dead and getting to it is way too much of a hassle on that particular motherboard, so virtualization defaults to off whenever it completely loses power. Which it unfortunately does on occasion like winter storms, or summer heat, or if the wind is blowing.
But hey, for the movies and shows we have on DVD/BD, as well as the music we’ve bought over the years, it does work for access from PCs and phones on the local network (Finamp + Jellyfin Media Player). I dabbled with IPTV for live TV replacement but found that only using totally free IPTV+metadata would take either much more work on no-virtualization Windows 10 than I’m willing to put up with, or have much more jank than my family is willing to put up with.
If “nearly every app” that people already use suddenly has a big warning on it, people will quickly decide the warnings are meaningless and start ignoring them, like Prop 65 warnings. Congratulations, we’ve moved the needle backwards.
You have to meet people where they’re at. I finally switched to Linux when MS introduced a feature I wanted no part in (Recall AI), but I would have given up within a day or two if the transition hadn’t been basically seamless. I was able to pick up right where I left off, using all the same apps I did on Windows except MusicBee RIP, but now I’m in a better position than before, on an open-source OS instead of closed-source. Now there’s a little less friction between me and better, freer software.
When I look at Firefox in Discover, it only shows the list of permissions the flatpak will be given out of the box, with no warning of it being “potentially unsafe.” This certainly does seem like the better way to handle it.
Also, the warning on the Flathub website is clickable - it expands into the full permissions list. Why it defaults to “no information except maybe dangerous” is beyond me.

If it was source available under a CLA, would it make sense for them to specify that they will retain control over the “official version” of the software? That would seem to imply they will not have control over unofficial versions, presumably differently-named forks.
Winamp will remain the owner of the software and will decide on the innovations made in the official version," explains Alexandre Saboundjian, CEO of Winamp.
This line gives me some hope that it will actually be open-source:
Winamp will remain the owner of the software and will decide on the innovations made in the official version.
Would they really bother to specify “official version” if it was only source-available and forks weren’t allowed?

The first result on Kagi search is this list which shows the movie years in parentheses so you can easily skip through just the ones from the 1980s. The other search results are more about the gag itself - first use of it by Charlie Chaplin, etc.
Atomic means the core OS packages are in an immutable container such that none of its individual components can be updated separately; instead the entire container is replaced with a newer version when the system is updated. This makes it much less likely for something to break during normal use, and easier to rollback updates if something does happen to break. The ideal use case is a containerized environment where each app you use is installed in its own container, like Docker, or is otherwise self-contained such as flatpak installers, and doesn’t rely on any of the system’s packages.
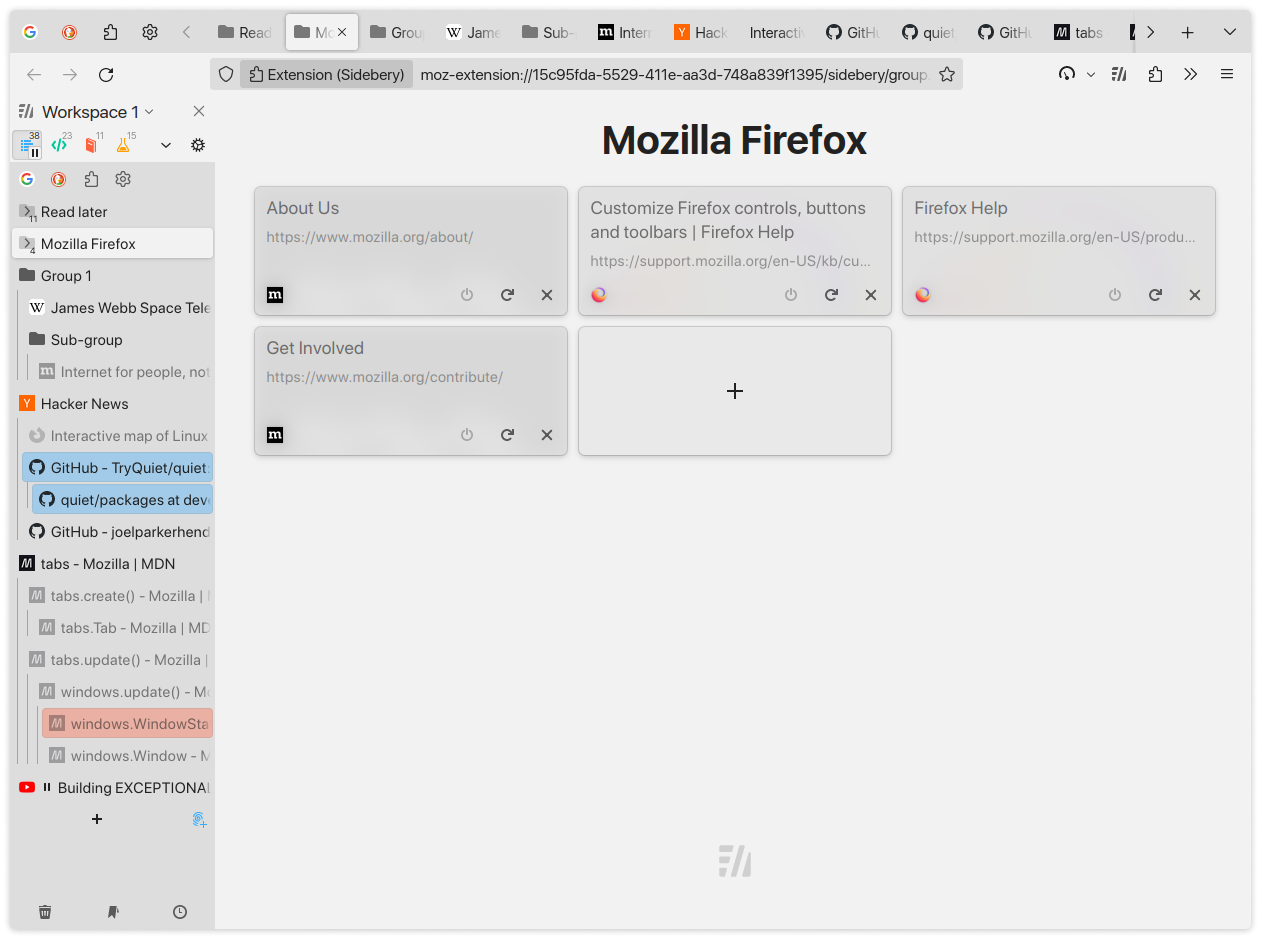
It has better customization, better performance, and tab groups. I used TST for many years, switched to Sidebery only a few months ago. You can do stuff like set it to where tabs only activate on releasing the mouse, so you can rearrange unloaded tabs without activating them, or make it so middle clicking the tab close button unloads it instead. You can also rename tabs!
What you’re missing is that “vertical tabs” in this context isn’t talking about tabs literally turned on their side. We’re talking about tabs that are still horizontal, but instead of arranging the tabs along the top of the screen, and shrinking their width when there’s no room left, they’re given a fixed width and arranged in a vertical list on one side of the screen. The best implementations of this (such as Sidebery, which the previous screenshot is from) also allow tabs to be nested in a collapsible tree structure.
You sound like you’d really like the tree-style tabs offered by Sidebery on Firefox, or that’s built into Edge. Give it a try!
There are several addons that organize the tabs in the sidebar with a vertical, tree-style layout, with nested tabs that can be collapsed, just like a classic folder structure. This is what GreyBeard was referring to earlier in the thread when he said “The tabs are in a tree hierarchy”.
Tree Style Tab has been around since 2007; Sidebery is much newer, and IMO looks and performs better.
When you’re keeping things in a tree structure for visual grouping and using containers to manage different logins, bookmarks will lose the tree structure, and you’ll have to specify which container to open it in. If your workflow involves a dozen tabs per context, locating the bookmarks and reopening them every time you switch contexts is a significant time and productivity loss.
Consider the classic Evidence Board (also known as string wall, crazy wall, conspiracy board, etc.). Saving everything to bookmarks is the equivalent of putting your board’s contents into a drawer, then pinning everything back up whenever you need to look at or update that particular conspiracy. It works, but it’s cumbersome, error-prone, and wastes a lot of time; you’d only do this if you only have one board but multiple things to inspect. Leaving tabs open and simply unloading the inactive tab trees is like having multiple separate boards where you just roll them into a closet when you aren’t using them.
{kind=link}
{kind=link}
You could try FreeFileSync. I use it for pretty much your exact use case, though my music library is much smaller and changes less often, so I haven’t tinkered with its automation. Manual sync works like a dream.